Some contents of this page was copied or inspired by Alex DeBries article on single table design. Alex is the authority on DynamoDB and his DynamoDB book is a must-read for anyone designing data models on DynamoDB.
Drawing board
On the previous page we encountered the following error:
http -b POST :8000/donation/create city=Haarlem address="Main street"
will return something along the lines of:

first_name is the primary key of our table, so it must be present in the item being saved to the table.
But of course, a blood donation event does not have a first_name.
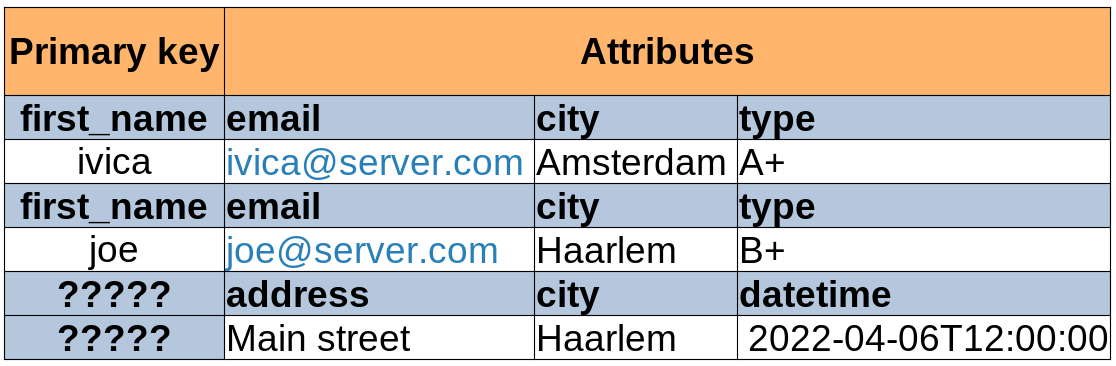
We tried to do what the table (screenshot) above shows and it is simply not possible. We could work around this in a few ways.
Using two tables
We could create a new table called donation_events. Having an extra table does not cost much, especially if it is
not being used.
However, adding another table would increase the complexity of our app. Permissions would have to be extended and maintained, additional environment variables would be needed etc.
What if another feature was requested, one that helps the organization (e.g. Red Cross) to keep track of volunteers? It would be silly to create a third table, no matter how inexpensive it is.
Storing the data separately means that fetching it is also separated; getting a list of donors for a donation in a city
would result in at least two API calls, and then some magic in code that stitches them together. There are no JOIN
operations in a NoSQL world.
Using multiple tables
Using a relational database
Maybe we made a mistake while planning this out. Using a relational database would make this problem trivial. Another table, a foreign key or two and voila.
Perhaps it’s time to talk to the client and tell them that “yeah, running this application would cost you money even when unused. Even during the night, when no sane person would refresh the UI to check for new blood donation drives”.
They might go with it but chances are they would abandon the whole idea.
Using a relational database
Single table design
Single table design is not an easy concept to grasp. There are no JOIN operations in DynamoDB because they are expensive -
they rely on scanning large amounts of data from multiple tables and doing comparisons under the hood.
DynamoDB was designed to offer consistent high performance no matter the scale. In order to deliver on that promise, it actively prevents you from performing operations or doing queries that would not scale.
Most developers have worked with JOIN operations at some point in their career, and you know what?
So did I and I like JOIN operations. I understand them and they worked well for me. So if the database system we chose
for this project does not support them at all, what can we do?
We can pre-join the data by creating item collections.
Item collections
We could simply organize similar data into item collections. All “donor” items could be saved in a way and also all “donation” items could be saved in another way. If you remember from our DynamoDB 101 page there must be one primary key defined. It is the unique identifier for the items in a table.
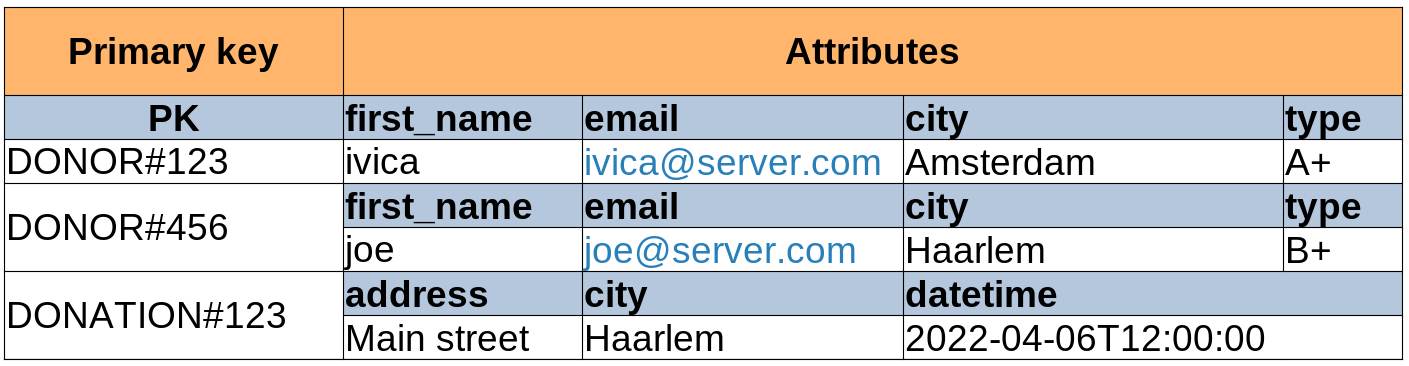
What if we chose a very generic primary key, something like PK? We can save both the first_name value and the
donation value under PK. PK for the win!
We still need a way to understand which value represents what item - what is a donor and what is a donation. This
can be achieved by “overloading” the keys, which essentially means storing more information in them than just the value.
An example of overloading the key would look like this:
We’ll implement code changes for this on the following page.
As we saw on the DynamoDB 101 page, Alex DeBrie’s resources are a gold mine. Watch part 1 and part 2 of his “Data modeling with DynamoDB presentation” for more information on single table design, access patterns and more.