Create a secondary index
Secondary indexes are a way to provide additional query patterns over the same data set. When creating the index, we define the partition key and the sort key, much in the same way as we did when creating a table. Additionally, we define the attributes that will be copied, or projected, from the table to the index.
One of the common design patterns with DynamoDB is using an inverted index. Inverted indexes are inverted because
their primary key PK and the sort key SK switch places. The primary key of our table will become the sort key of
the index, while the sort key of the table will become the primary key of the index.
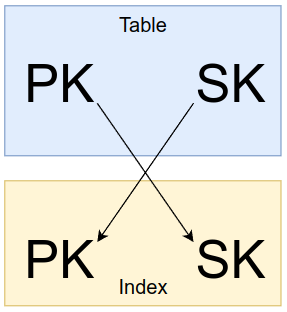
Inverting the keys is useful because it allows us to query the “other side” of a one-to-many relationship. Previously we
could have only used the DONOR#abcd1234 (the PK value) to do a Query operation, but now we can also use the SK value.
But… where is the SK value?
Adding the sort key
There’s something wickedly fun about deleting tables. Probably because you’re not supposed to, unless it’s the dev or sandbox account. It is impossible to add a sort key to an existing DynamoDB table. That’s why we will delete ours and create it again. It’ll only take a few seconds.
Delete the table:
aws dynamodb delete-table --table-name $WORKSHOP_NAME-savealife-$ENV --profile workshop
Create the table with the sort key:
aws dynamodb create-table --table-name $WORKSHOP_NAME-savealife-$ENV \
--profile workshop \
--attribute-definitions AttributeName=PK,AttributeType=S AttributeName=SK,AttributeType=S \
--key-schema AttributeName=PK,KeyType=HASH AttributeName=SK,KeyType=RANGE \
--billing-mode PAY_PER_REQUEST
We have added the SK attribute with AttributeName=SK,AttributeType=S and included it in the key schema with
AttributeName=SK,KeyType=RANGE.
Now that the sort key exists in the table, we have to provide values for it when inserting new items. Let’s make the necessary changes.
Change PutItem code
Keys in DynamoDB tables must have values, and our table was recently expanded with a sort key. So, what would be a good
value to put as the sort key? How about CITY#CITY_NAME_HERE?
Our donor_signup() function in db_donor.py will have the highlighted line added.
self._table.put_item(
Item={
"first_name": donor_dict.get("first_name"),
"type": donor_dict.get("type"),
"email": donor_dict.get("email"),
"PK": f"DONOR#{uid}",
"SK": f"CITY#{donor_dict.get('city')}"
}
)Because we’re using the single-table design pattern for writing multiple different entities into a single table, all of
those entities must have both keys filled in now. So lets change the donation_create() in db_donation.py to contain
the highlighted line:
self._table.put_item(
Item={
"city": donation_dict.get("city"),
"datetime": donation_dict.get("datetime"),
"address": donation_dict.get("address"),
"PK": f"DONATION#{uid}",
"SK": f"CITY#{donation_dict.get('city')}"
}
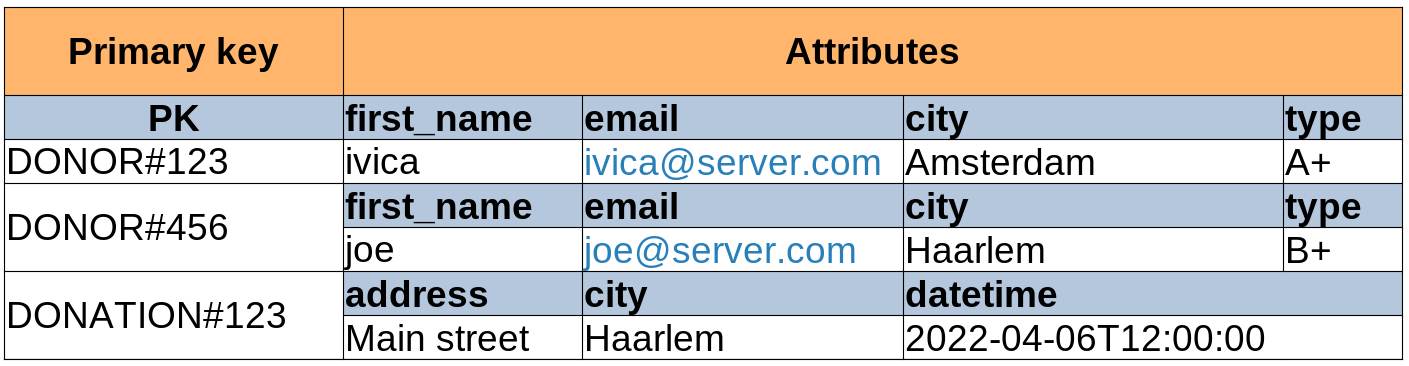
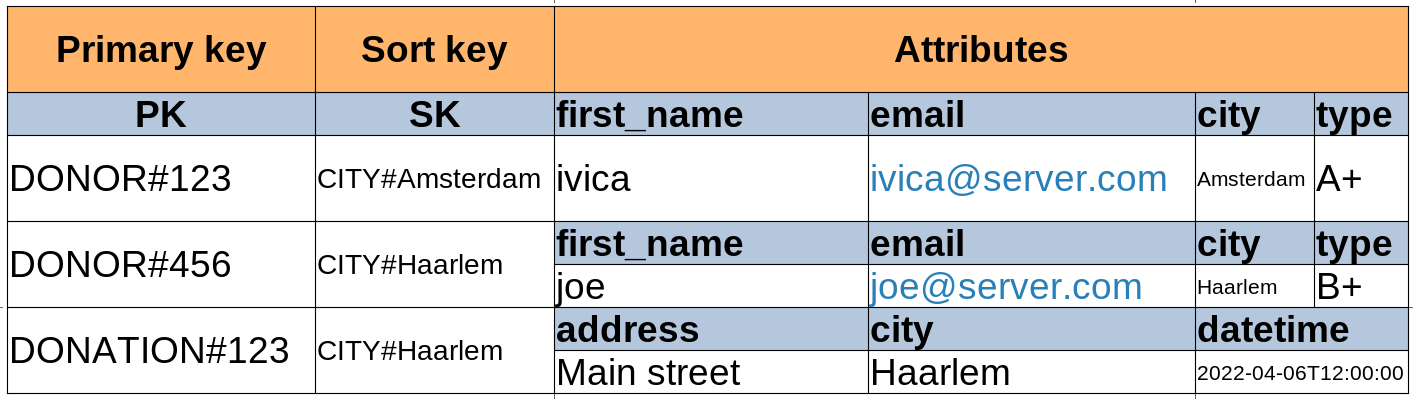
)Below are the “before” and “after” designs of our data model:
became
Inverting the keys and creating the index
Inverting the keys is useful because it allows us to query the “other side” of a one-to-many relationship. Previously we
could have only used the DONOR#abcd1234 (the PK value) to do a Query operation, but now we can also use the SK value.
Once the index is created with these inverted keys, its data model will look like this:
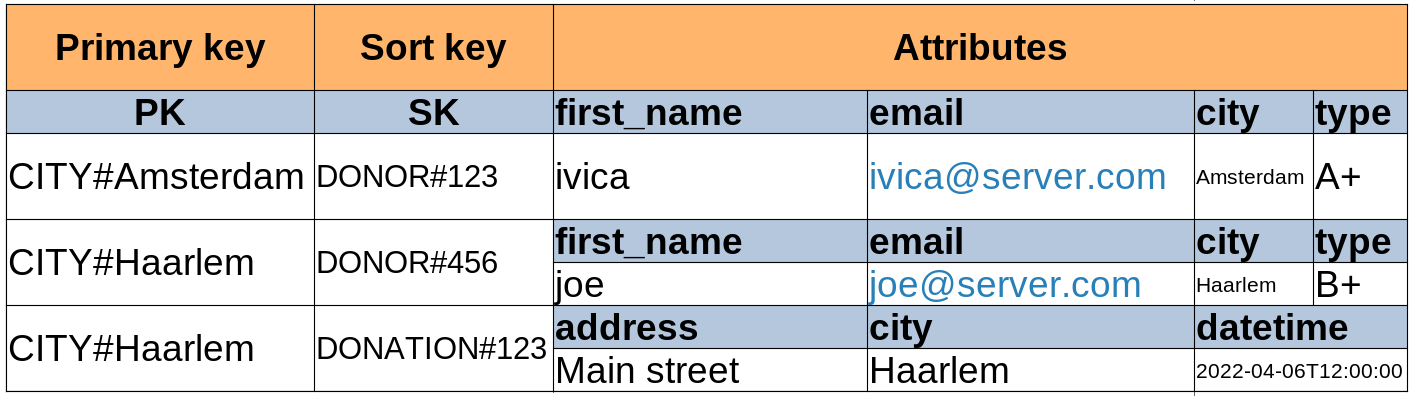
which will give us the possibility to query for all donors from a specific city, and also for all donations from a specific city, or both.
If we were to translate these into SQL:

and

Create the index
Indexes can, luckily, be added to existing tables, and for that we will use the update-table functionality.
aws dynamodb update-table --table-name $WORKSHOP_NAME-savealife-$ENV \
--attribute-definitions AttributeName=PK,AttributeType=S AttributeName=SK,AttributeType=S \
--global-secondary-index-updates \
"[
{
\"Create\": {
\"IndexName\": \"SK-PK-index\",
\"KeySchema\": [{\"AttributeName\":\"SK\",\"KeyType\":\"HASH\"},
{\"AttributeName\":\"PK\",\"KeyType\":\"RANGE\"}],
\"Projection\":{
\"ProjectionType\":\"ALL\"
}
}
}
]"
If you have a keen eye, you may have noticed that we inverted the keys by specifying that SK is of type HASH and PK
is of type RANGE (“primary key” is the same as “hash key”, sort key is the same as “range key”)
Creating the index may take a few minutes, depending on the amount of data to be projected (copied). And that’s exactly what an index is - a copy of data with a structure that is different from the table structure. And just like tables, they can be queried.
"ProjectionType": "ALL" will copy all the attributes into the index, which will make our life easier once we start
to query the index.
Let’s explore how that is done on the next page.