Query a secondary index
On the previous page we looked at how a data model for the secondary index might look like and we created one with the following data model:
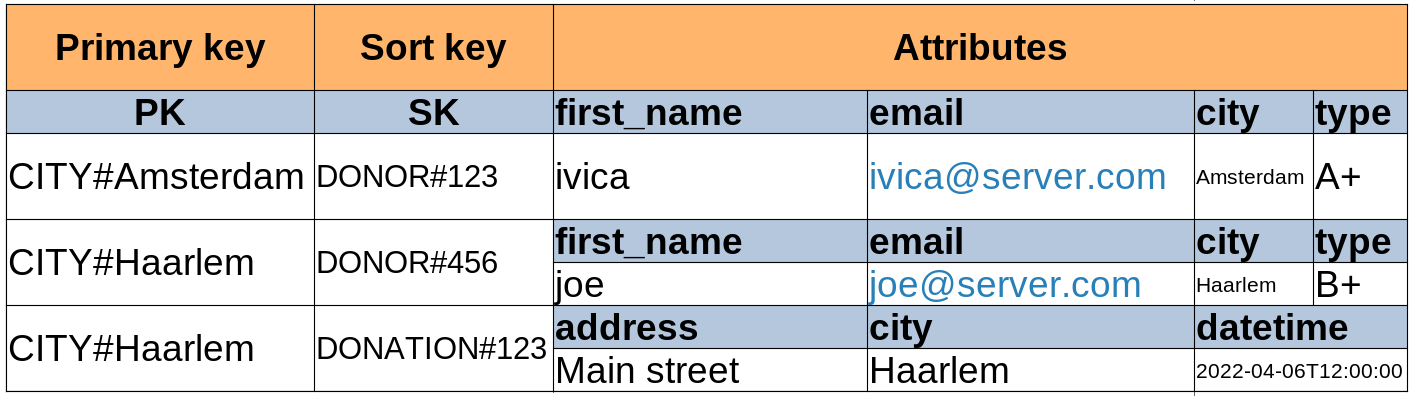
An index is a copy of data from the table, with a structure that is different from the table structure. And just like tables, they can be queried. Let’s look into how that can be done.
Insert dummy data
# two donation events
http -b POST $(chalice url)/donation/create city=Amsterdam address="Main street" datetime="2022-04-06T12:00:00"
http -b POST $(chalice url)/donation/create city=Haarlem address="Other street" datetime="2022-04-06T12:00:00"
# one donor from Amsterdam
http -b POST $(chalice url)/donor/signup first_name="r2d2" email="r2d2@server.com" city="Amsterdam"
# two from Haarlem
http -b POST $(chalice url)/donor/signup first_name="c3po" email="c3po@server.com" city="Haarlem"
http -b POST $(chalice url)/donor/signup first_name="obiwan" email="kenobi@server.com" city="Haarlem"
And this is how the data looks in our table when we scan the table:
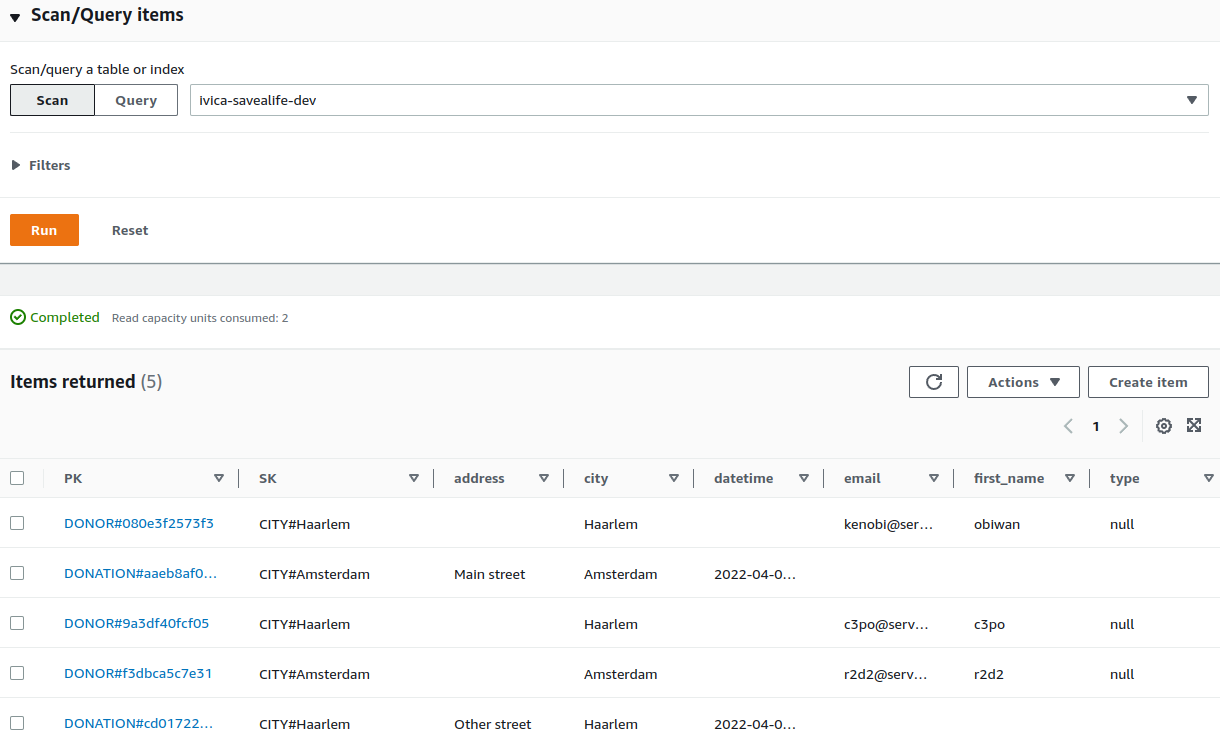
Scan the index
Notice how the upper part of the screenshot contains a sentence “Scan/query a table or index”? Lovely!
We chose that our SK-PK-index index will contain just the table keys and we aptly named those keys PK and SK.
Scanning the index reveals that:
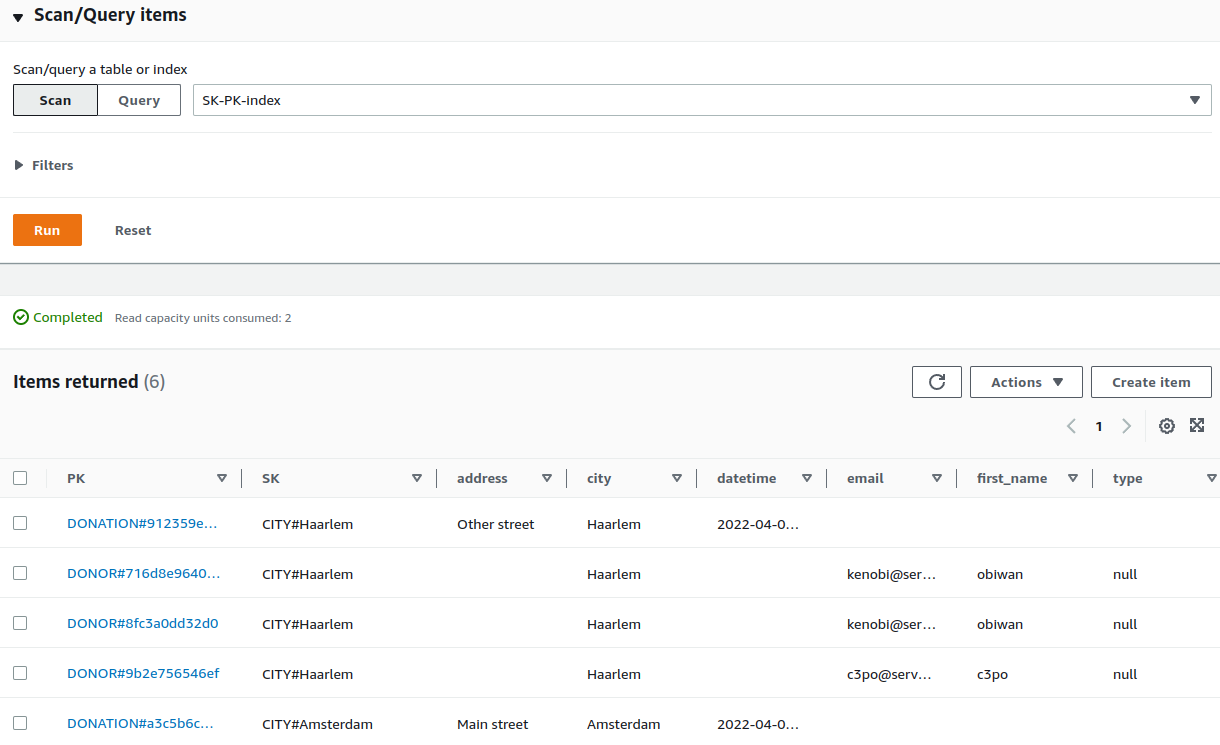
But we are here to query the index (and also scans are expensive! notice how it says “Read capacity units consumed: 2”?)
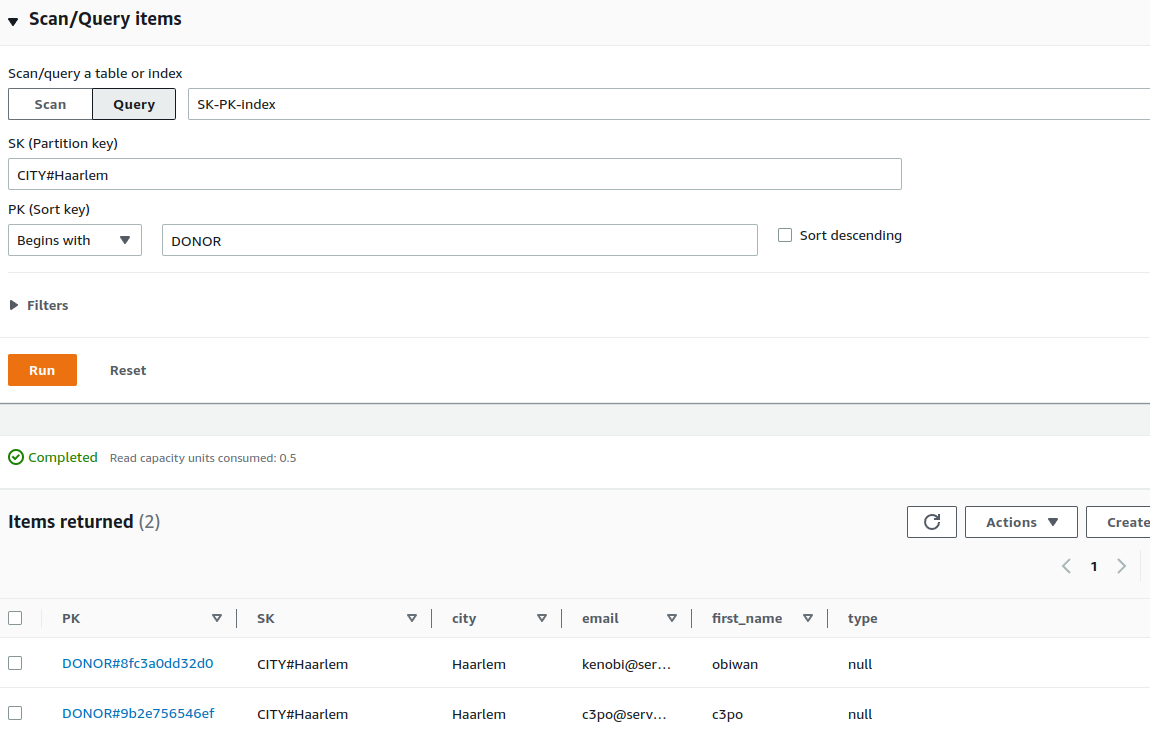
Query the index
We can query the index by specifying that SK (which is the partition key in the case of this index) equals
CITY#Haarlem, which will result in a mix of donors and donations that either live or are organized in Haarlem.
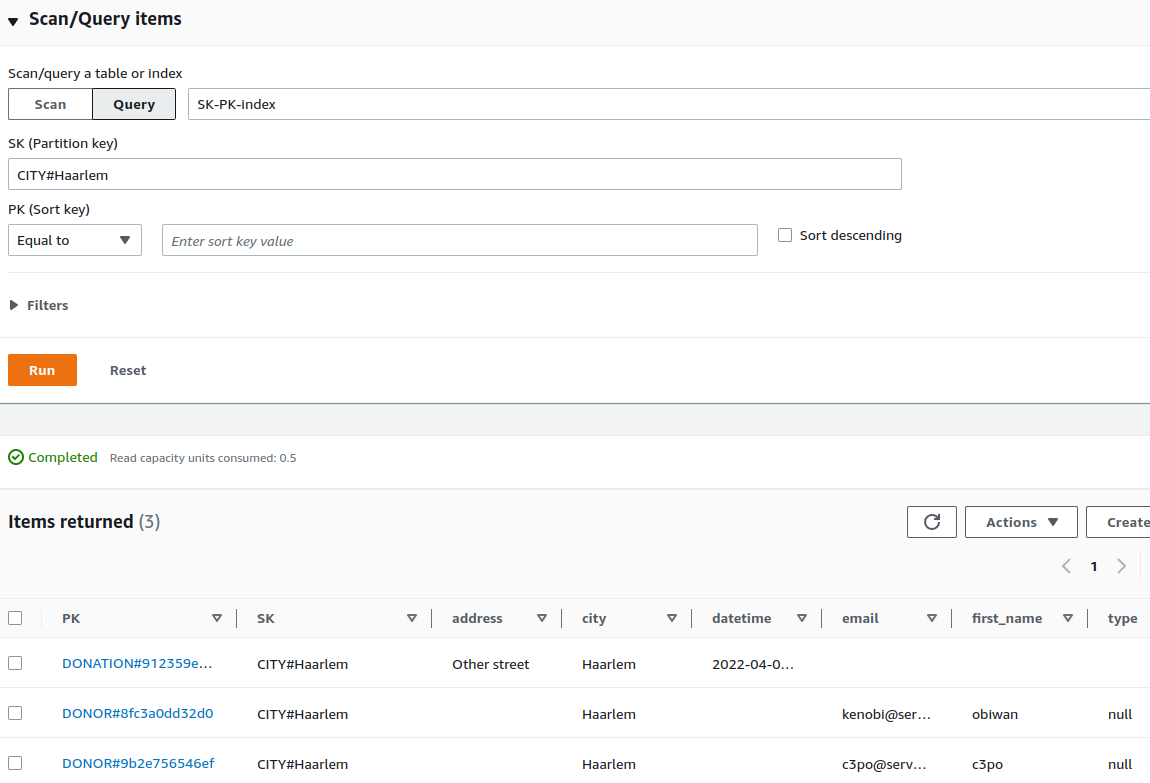
From there we can easily make our query more precise by specifying that the PK (which is the sort key in the case of
this index) begins with DONOR which is exactly what we need for the feature of our app; get all donors from a city.
Changing the PK value to DONATION will result in a list of all donations in this specific city.
And what about those capacity units? “Read capacity units consumed: 0.5” which will result in a much lower overall
cost of using the application when compared to simply running Scan operations.